搜索到
36
篇与
科长
的结果
-
 simple-nvr:开源的视频监控 NVR 项目 项目简介Simple NVR 是一个开源的网络视频录像机(NVR),它被设计为在低资源消耗的廉价硬件上运行,例如配备硬盘的 Raspberry Pi。这个项目能够实现24/7的视频流从网络摄像头保存下来,并且可以通过一个基础的Web界面进行文件浏览。Simple NVR 需要安装 FFmpeg,并且配置要求最低。该项目使用 Node.js 编写,并利用 FFmpeg 进行视频处理。部署教程Simple NVR 依赖于 Node 环境和 FFmpeg 来处理视频流,因此你需要确保 Node 和 FFmpeg 已经安装在你的系统上。运行通过 Git 克隆仓库到本地或者直接下载 ZIP 文件并解压:git clone https://github.com/TomHumphries/simple-nvr.git然后进入到 Simple NVR 的目录中,使用 npm 安装所需的依赖:cd simple-nvr npm install然后编辑项目目录下的cameras.json添加我们的监控设备:监控需要支持 rtsp 推流才可以![ { # 监控名称 "name": "example-camera-name", # 监控的rtsp推流地址 "url": "rtsp://192.168.255.255:554/11" } ]添加完成之后还需要配置监控录像存放的位置,修改存放的位置需要编辑项目根目录下的storage.json文件:{ # 录像存放位置 "rootpath": "/media/pi/ExternalHDD1" }然后启动服务:node nvr.js这个时候NVR就开始工作了,后台会持续录像,我们也可以启动web管理界面来查看摄像头的录像文件和实时画面,通过启动nvr-browser.js:node nvr-browser.js访问3000端口:该服务会每五分钟保存一下视频片段,当天结束后会自动生成24小时的长录像文件。使用pm2运行PM2(Process Manager 2)是一个流行的Node.js应用程序的进程管理器。它允许您在多种环境中(如生产环境)管理和保持应用程序的稳定性。可以通过下面的命令安装pm2工具:npm install pm2@latest -g然后启动NVR服务:# 启动录像服务 pm2 start nvr.js --name nvr # 启动 web 服务 pm2 start nvr-browser.js --name nvr-web然后可以通过下面的命令查看运行的服务:pm2 list
simple-nvr:开源的视频监控 NVR 项目 项目简介Simple NVR 是一个开源的网络视频录像机(NVR),它被设计为在低资源消耗的廉价硬件上运行,例如配备硬盘的 Raspberry Pi。这个项目能够实现24/7的视频流从网络摄像头保存下来,并且可以通过一个基础的Web界面进行文件浏览。Simple NVR 需要安装 FFmpeg,并且配置要求最低。该项目使用 Node.js 编写,并利用 FFmpeg 进行视频处理。部署教程Simple NVR 依赖于 Node 环境和 FFmpeg 来处理视频流,因此你需要确保 Node 和 FFmpeg 已经安装在你的系统上。运行通过 Git 克隆仓库到本地或者直接下载 ZIP 文件并解压:git clone https://github.com/TomHumphries/simple-nvr.git然后进入到 Simple NVR 的目录中,使用 npm 安装所需的依赖:cd simple-nvr npm install然后编辑项目目录下的cameras.json添加我们的监控设备:监控需要支持 rtsp 推流才可以![ { # 监控名称 "name": "example-camera-name", # 监控的rtsp推流地址 "url": "rtsp://192.168.255.255:554/11" } ]添加完成之后还需要配置监控录像存放的位置,修改存放的位置需要编辑项目根目录下的storage.json文件:{ # 录像存放位置 "rootpath": "/media/pi/ExternalHDD1" }然后启动服务:node nvr.js这个时候NVR就开始工作了,后台会持续录像,我们也可以启动web管理界面来查看摄像头的录像文件和实时画面,通过启动nvr-browser.js:node nvr-browser.js访问3000端口:该服务会每五分钟保存一下视频片段,当天结束后会自动生成24小时的长录像文件。使用pm2运行PM2(Process Manager 2)是一个流行的Node.js应用程序的进程管理器。它允许您在多种环境中(如生产环境)管理和保持应用程序的稳定性。可以通过下面的命令安装pm2工具:npm install pm2@latest -g然后启动NVR服务:# 启动录像服务 pm2 start nvr.js --name nvr # 启动 web 服务 pm2 start nvr-browser.js --name nvr-web然后可以通过下面的命令查看运行的服务:pm2 list -
Spark:基于浏览器来批量管理设备的平台 项目简介Spark 通过简单的浏览器界面,提供跨平台的远程管理能力,适用于各种操作系统,包括 Windows、Linux 和 MacOS。其目标是让用户能轻松地远程管理不同设备,适合需要集中管理多台设备的场景。核心功能进程管理:支持查看和终止正在运行的进程,帮助用户高效管理系统资源。网络流量监控:实时监控网络活动,确保网络安全和性能。文件管理:包括文件浏览、上传、下载、编辑和删除等功能,方便文件操作。桌面监控:支持远程查看设备桌面和截屏功能,助力远程支持和问题诊断。系统信息查看:获取详细的操作系统信息,帮助用户了解设备状态。终端访问:提供远程终端访问,便于执行命令行操作。系统控制:支持远程关机、重启、注销等操作。安全与隐私数据保护:Spark 不会收集用户数据,所有通信仅在客户端和用户的服务器之间进行。使用须知:项目仅供学习和研究使用,禁止任何形式的非法用途。用户需自行承担使用风险。搭建教程开源地址: https://github.com/XZB-1248/Spark下载二进制文件前往下方的地址下载对应平台的二进制文件:https://github.com/XZB-1248/Spark/releases编辑配置文件将下载下来的文件进行解压,然后在文件目录中创建config.json文件:参照以下内容进行填写:{ "listen": ":8000", "salt": "123456abcdef", "auth": { "username": "password" }, "log": { "level": "info", "path": "./logs", "days": 7 } }参数解析:listen:监听哪个端口启动服务。salt:随意填写,长度不大于24。auth:访问web界面的用户名和密码即:用户名:密码。其他的参数可以不用改变,以上的参数可以参考进行调整。启动服务通过命令直接启动服务即可:然后通过在浏览器中访问8000端口进入控制台:添加设备在浏览器中点击生成客户端,根据不同的架构来生成对应的架构客户端,然后到目标设备中运行使其上线到远控平台上:成功运行后即可看到客户端已经上线了:免责声明本文档仅用于提供信息和教育目的。Spark 是一个开源项目,仅供合法和道德的用途。用户在使用 Spark 时,应遵守所有适用的法律法规。由于不当使用可能导致的任何损害、数据丢失或其他后果,本文作者和开发者概不负责。
-
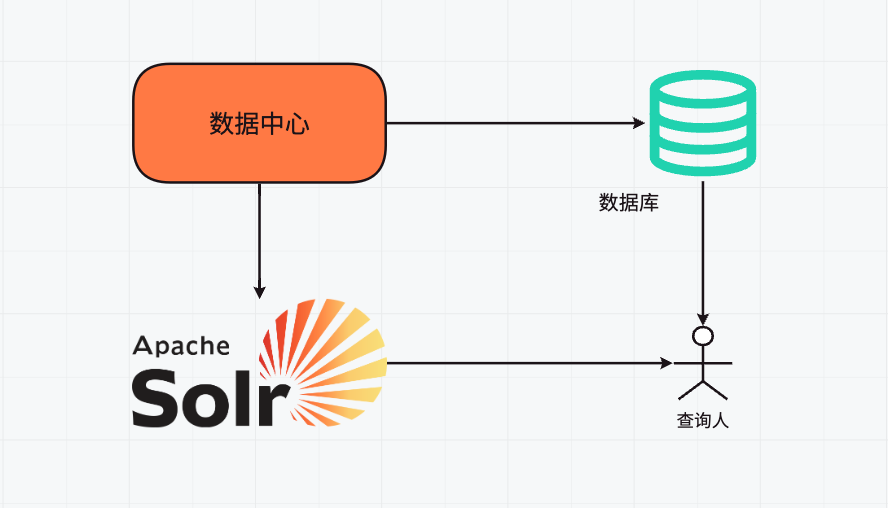
SpringBoot 集成 Solr 实现高效全文检索服务 简介Solr 是一个基于 Apache Lucene 构建的开源搜索平台。它提供了强大的搜索功能、高效的索引机制和丰富的配置选项,使得开发者能够轻松构建高性能的搜索应用。Solr 具有易于使用的 Web 管理界面,方便进行配置和监控。它支持多种数据格式的索引和搜索,能够处理大量的数据,并提供了诸如分页、排序、过滤、高亮显示搜索结果等功能。有了 MySQL 还有必要用 Solr 吗即使已经使用了 MySQL 这样的关系型数据库,在某些情况下使用 Solr 仍然是有必要的。MySQL 擅长处理结构化数据的存储和事务操作,但在搜索功能方面存在一些局限性。例如,对于复杂的全文搜索、模糊搜索、相关性排序等需求,MySQL 可能无法提供高效和灵活的解决方案。而 Solr 专门为搜索进行了优化,能够快速处理大规模的文本数据搜索,并提供更精确的搜索结果排序和相关性计算。举例来说,如果您的应用需要快速搜索大量的文章内容、产品描述等文本信息,并且对搜索的响应速度和准确性要求较高,那么单独依靠 MySQL 可能无法满足需求,此时结合 Solr 可以显著提升搜索体验。另外,如果需要实现实时搜索、动态索引更新等功能,Solr 也更具优势。安装Solr下载运行前往solr的官方下载地址:https://solr.apache.org/downloads.htmlSolr 9.x 版本最低运行要求是 Java 11,我一直使用的是 Java 8 所以这里我将使用 Solr 8.x 作为本次的教程版本。下载后将其解压会得到如下的目录结构:打开终端,进入bin目录中启动Solr服务:Windows用户则只需要执行下面的命令:solr start安装中文分词器中文具有独特的语言结构和语义表达,不像英文等语言,单词之间通常有明显的空格分隔。如果直接使用 Solr 默认的分词器处理中文文本,可能会将中文拆分成单个的汉字,而不是按照中文的词语进行切分。前往Maven仓库下载分词依赖:https://mvnrepository.com/artifact/com.github.magese/ik-analyzer/8.5.0将下载下来的 ik-analyzer-8.5.0.jar 放入到 solr-8.11.3/server/solr-webapp/webapp/WEB-INF/lib 中我们在终端使用命令创建一个 core 来测试一下分词器: ./solr create -c ik_core 然后在 solr-8.11.3/server/solr 下可以看到一个名为 ik_core 的目录:在 conf 目录下编辑 managed-schema 文件并写入以下内容:<!-- IKAnalyzer--> <fieldType name="text_ik" class="solr.TextField" autoGeneratePhraseQueries="false"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" type="index"> </analyzer> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" type="query"> </analyzer> </fieldType>重启Solr服务:测试分词器在 Solr Admin 中,也就是solr的web界面,选择我们创建的 ik_core 在 Analysis 中测试分词效果(Analyse Fieldname / FieldType 选择为 text_ik):集成到SpringBoot创建SpringBoot项目SpringBoot项目的创建可以借助IDE完成,这里就不再叙述了。添加maven依赖在项目的 pom.xml 中添加新的依赖:<dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-solrj</artifactId> <version>8.11.3</version> </dependency>创建配置在application.yml中添加solr的配置信息:solr: host: http://127.0.0.1:8983/solr创建配置类:import org.apache.solr.client.solrj.SolrClient; import org.apache.solr.client.solrj.impl.HttpSolrClient; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class SolrConfig { @Value("${solr.host}") private String solrHost; @Bean public SolrClient solrClient() { return new HttpSolrClient.Builder(solrHost).build(); } }创建文档索引在查询数据之前,我们需要在solr中导入我们的数据,并建立索引。第一种方式来添加文档比较简单:@Resource private SolrClient solrClient; public void indexQuestion() throws Exception{ // 创建一个文档对象 SolrInputDocument inputDocument = new SolrInputDocument(); // 添加字段 inputDocument.addField("id", "1"); inputDocument.addField("name", "名称1"); inputDocument.addField("content", "内容1"); inputDocument.addField("category", "类别1"); // 将文档写入索引库中 solrServer.add("ik_core", inputDocument); // 提交 solrServer.commit("ik_core"); }第二种方式则是实用Java Bean的方式,其字段属性使用Solr提供的的 @Field 注解标柱:@Data public class Document { @Field private String id; @Field private String name; @Field private String content; @Field private String category; }然后实例化Bean,并将其添加到我们创建的 ik_core 中进行索引:@Resource private SolrClient solrClient; public boolean indexQuestion() throws SolrServerException, IOException { // 实例化并添加 Document 对象 Document doc1 = new Document(); doc1.setId("1"); doc1.setName("国内新能源汽车销量持续攀升"); doc1.setContent("今年以来,国内新能源汽车市场表现强劲,销量不断增长。各大厂商纷纷推出新款车型,技术创新不断。"); doc1.setCategory("汽车"); solrClient.addBean("ik_core", doc1); Document doc2 = new Document(); doc2.setId("2"); doc2.setName("国内电商行业发展新趋势"); doc2.setContent("随着数字化转型的加速,国内电商行业呈现出直播带货、社交电商等新趋势,消费者购物方式发生显著变化。"); doc2.setCategory("电商"); solrClient.addBean("ik_core", doc2); Document doc3 = new Document(); doc3.setId("3"); doc3.setName("国内5G网络建设加速推进"); doc3.setContent("国内5G网络覆盖范围持续扩大,为智能制造、智慧城市等领域的发展提供了有力支撑。"); doc3.setCategory("通信"); solrClient.addBean("ik_core", doc3); Document doc4 = new Document(); doc4.setId("4"); doc4.setName("国内旅游市场逐渐复苏"); doc4.setContent("在疫情防控形势好转的背景下,国内旅游市场迎来复苏,各地旅游景点游客数量逐步增加。"); doc4.setCategory("旅游"); solrClient.addBean("ik_core", doc4); Document doc5 = new Document(); doc5.setId("5"); doc5.setName("国内医疗改革取得新进展"); doc5.setContent("近年来,国内医疗改革不断深化,医保政策优化,医疗服务质量得到提升。"); doc5.setCategory("医疗"); solrClient.addBean("ik_core", doc5); // 提交 UpdateResponse updateResponse = solrClient.commit("ik_core"); return updateResponse != null && updateResponse.getStatus() == 0; }当有了这些数据后,我们即可对这些数据进行检索操作,第一次我们写简单点进行查询:public void query() throws SolrServerException, IOException { // 创建查询语句 SolrQuery query = new SolrQuery(); // 设置查询条件 query.set("q", "id:1"); // 执行查询 QueryResponse queryResponse = solrClient.query("ik_core", query); // 取文档列表 SolrDocumentList documentList = queryResponse.getResults(); for (SolrDocument solrDocument : documentList) { System.out.println("id:"+solrDocument.get("id")+" "); System.out.println("名称:"+solrDocument.get("name")+" "); System.out.println("内容:"+solrDocument.get("content")+" "); System.out.println("类别:"+solrDocument.get("category")+" "); } // 也可以反序列化为Java Bean List<Document> documents = queryResponse.getBeans(Document.class); for (Document document : documents) { System.out.println("id:" + document.getId()); System.out.println("名称:" + document.getName()); System.out.println("内容:" + document.getContent()); System.out.println("类别:" + document.getCategory()); } }接下来可以构造条件丰富的查询: public void query() throws Exception { // 创建查询语句 SolrQuery query = new SolrQuery(); // 设置查询关键字 query.set("q", "国内"); // 按照id降序排列 query.setSort("id", SolrQuery.ORDER.desc); // 分页条件 query.setStart(0); query.setRows(2); // 在指定的字段中进行查询 query.set("df", "name"); // 设置高亮 query.setHighlight(true); // 设置高亮的字段 query.addHighlightField("name,content"); // 设置高亮的样式 query.setHighlightSimplePre("<font color='red'>"); query.setHighlightSimplePost("</font>"); // 执行查询 QueryResponse queryResponse = solrClient.query("ik_core", query); // 返回高亮显示结果 Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting(); System.out.println(highlighting); // 获取文档列表 SolrDocumentList documentList = queryResponse.getResults(); System.out.println("总记录数:" + documentList.getNumFound()); for (SolrDocument solrDocument : documentList) { System.out.println("id:" + solrDocument.get("id") + " "); System.out.println("名称:" + solrDocument.get("name") + " "); System.out.println("内容:" + solrDocument.get("content") + " "); System.out.println("类别:" + solrDocument.get("category") + " "); } }删除文档则可以使用id字段进行删除:public void deleteQuestion() throws SolrServerException, IOException { solrClient.deleteById("ik_core", "1"); // 提交 solrClient.commit("ik_core"); }总体的来说 Solr 是一款开源的高性能搜索平台,具有强大搜索功能、可扩展性、丰富特性、灵活配置且易于集成,能满足各种复杂搜索和数据管理需求。
-
UpSnap:搭建开源的网络唤醒服务 项目介绍UpSnap是在Github中开源的一个局域网唤醒工具,它使用SvelteKit、Go、PocketBase和nmap编写,可以通过网络唤醒局域网内的设备。UpSnap的主要作用是允许用户通过网络发送特定的数据包(称为“魔法包”)来启动处于休眠或关机状态的计算机或其他设备,这项技术通常被用于系统管理、远程访问和各种自动化场景中。主要功能一键设备唤醒仪表盘:用户可以通过简单的界面唤醒设备。定时事件自动化:支持通过 Cron 任务设置自动化操作。端口扫描:可以选择性扫描网络端口。设备发现:支持网络扫描(需要 nmap)。用户管理:提供安全的用户管理功能。国际化支持:支持多语言。丰富的主题:提供 29 种主题选择。Docker 支持:提供适用于多种架构的 Docker 镜像,包括 amd64、arm64、arm/v7、arm/v6。自托管:支持自行托管部署。项目地址Github: https://github.com/seriousm4x/UpSnap搭建教程二进制部署根据自身的系统架构,可前往Github中的开源仓库releases中下载对应架构的软件包:https://github.com/seriousm4x/UpSnap/releasesLinux 用户可参考一下命令运行:# 在 8090 端口启动web服务 sudo ./upsnap serve --http=0.0.0.0:8090Windows 用户则需要打开终端,并在软件根目录下执行命令启动:upsnap.exe serve --http=0.0.0.0:8090使用Docker部署使用 docker 运行服务的服务能够脱离平台的限制,可以快速运行在群晖、极空间等各种NAS服务之间:docker run -d \ --restart unless-stopped \ --network host \ --name upsnap \ -v /path/to/your/data:/app/pb_data \ ghcr.io/seriousm4x/upsnap:latest在NAS中运行,例如群晖上更推荐使用docker compose的方式:services: upsnap: container_name: upsnap image: ghcr.io/seriousm4x/upsnap:4 # images are also available on docker hub: seriousm4x/upsnap:4 network_mode: host restart: unless-stopped volumes: - ./data:/app/pb_data访问配置搭建完成后,通过访问IP+8090端口访问网络唤醒服务,并根据提示进行配置:初始化完成后,在首页添加我们需要远程唤醒的局域网内的设备:除了手动配置,还支持扫码内网指定网段内的设备进行快速添加:
-
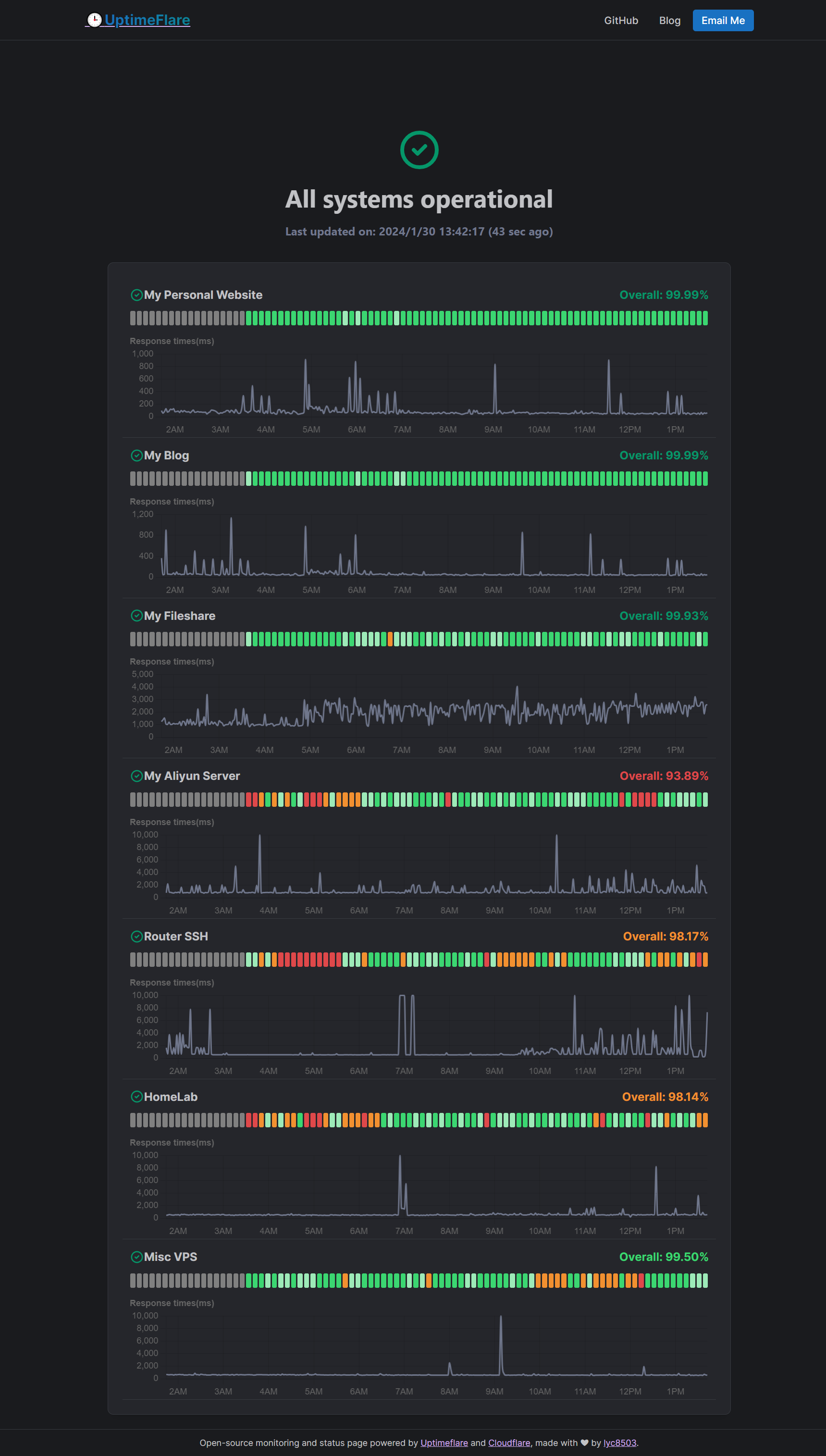
UptimeFlare:一个开源的服务器监控工具 项目简介UptimeFlare 是一个开源的服务器监控工具,它基于 Cloudflare Workers 构建,提供了一个无服务器的监控和状态页面系统。这个工具支持HTTP/HTTPS/TCP端口的监控,并且可以从全球超过310个城市的节点进行地理位置特定的检查。UptimeFlare 还允许用户自定义HTTP请求的方法、头部和正文,以及自定义状态码和关键词检查功能。此外,它还支持可定制的Webhook,确保用户能够及时获取系统状态的变化信息演示地址: https://uptimeflare.pages.dev/项目特点UptimeFlare 的一些主要特点包括:开源且易于部署,用户可以在10分钟内完成设置,无需安装任何本地开发工具。免费使用,利用Cloudflare Workers的免费层,为用户提供预算友好的监控解决方案。支持高达50个每两分钟检查一次的任务。提供全球化监控,确保全面了解服务性能。高度定制化,包括自定义状态页面、请求配置和Webhooks,满足各类需求官方信息由于 UptimeFlare 是部署在 Cloudflare Workers 中的,官方也给出了非常详细的操作指南,内容过多我也没有进行整理,大家可以参考一下官方给出的步骤:https://github.com/lyc8503/UptimeFlare/wiki/Quickstart
-
WinSW:一个可以将Jar或exe注册成Windows系统服务的工具 项目简介WinSW 是一款可在 Windows 系统中应用的开源工具。它能够让用户把任意可执行文件(例如 exe 或者 jar 文件甚至是 bat 脚本)包装转化为 Windows 服务,进而达成自动化管理的目的。通过使用 WinSW,用户可以毫不费力地进行服务的安装、启动、停止以及卸载操作。主要特性开源:WinSW基于MIT许可证,完全开源,允许自由修改和分发。跨版本兼容:支持从Windows XP至Windows Server 2019等多个Windows版本。可扩展:支持通过插件机制添加自定义行为,如发送邮件通知、记录额外的日志信息等。安全可靠:遵循最小权限原则,服务运行时仅需有限的权限,提高了系统的安全性。简洁易用:使用极其简单,只需要一个命令行接口和一个XML配置文件。使用教程需要前往Github开源仓库中下载对应的软件包:https://github.com/winsw/winsw/releases我这里给大家演示一下如何将 Jar 注册到系统服务中,我们将下载好的 WinSW 工具和Jar包放在一起,如图:我们需要将WinSW-x64.exe重新命名成plugin.exe(这里命名根据自己随意命名),然后同时创建一个与exe同名的xml文件,最终效果如图:核心的配置都在xml中:常见的关键元素的解释:id:服务的唯一标识符。name:服务的显示名称。description:服务的描述。executable:要运行的程序的路径。arguments:传递给程序的参数。startmode:服务的启动类型Automatic(自动)、Manual(手动)或Disabled(禁用)。depend:服务依赖的其他服务。logpath:日志文件的存放路径。log:日志记录方式(大小轮转、时间轮转、追加)。通过下方的命令进行注册:plugin.exe install最终的效果如图所示:我们可以在windows上的服务中手动启停服务,也可以通过终端命令:# net start 服务名 net start plugin 包括停止服务:net stop plugin我们如果不想继续使用服务注册了,可以将已注册的服务进行卸载:plugin.exe uninstall由此可见,通过使用WinSW,用户可以轻松地将应用程序作为Windows服务进行部署和管理,提高了应用程序的可用性和可维护性。
-
搭建Kafka最新版本 安装Java环境在oracle官网下载jdk1.8 ,官网地址https://www.oracle.com/java/technologies/downloads/#java8。上传JDK下载完成后上传到用户根目录并重命名为jdk.tar.gz:tar -xf jdk.tar.gz -C /opt/jdk配置环境变量echo "" >> /etc/profile echo "# JDK 8 Environment Variables" >> /etc/profile echo "export JAVA_HOME=/opt/jdk" >> /etc/profile echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile source /etc/profile验证安装[root@test1 ~]# java -version java version "1.8.0_391" Java(TM) SE Runtime Environment (build 1.8.0_391-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.391-b13, mixed mode)安装Kafka最新版本在写这篇文章的时候,目前最新版本是3.6.0版本下载最新版本cd /opt && wget https://downloads.apache.org/kafka/3.6.0/kafka_2.13-3.6.0.tgz 解压tar -xzf kafka_2.13-3.6.0.tgz配置Kafka进入解压目录:cd kafka_2.13-3.6.0打开config/server.properties文件进行配置:vi config/server.properties根据自己的需求进行调整:broker.id:Kafka代理的唯一标识符。listeners:Kafka监听器的主机和端口。默认情况下,Kafka使用PLAINTEXT://:9092。log.dirs:Kafka日志文件的目录。zookeeper.connect:Zookeeper的主机和端口。默认情况下,Kafka使用localhost:2181。启动Kafka# 先启动 zookeeper bin/zookeeper-server-start.sh -daemon config/zookeeper.properties # 再启动 kafka bin/kafka-server-start.sh -daemon config/server.properties验证以下的所有操作都是在/opt/kafka_2.13-3.6.0中进行:创建主题bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1发布消息到test-topic主题:bin/kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:9092在新终端窗口中,消费来自test-topic主题的消息:bin/kafka-console-consumer.sh --topic test-topic --bootstrap-server localhost:9092 --from-beginning
-
-
-